











1. Topic
주제 선정
: 인공지능 연산을 빠르게 수행할 수 있는 AI HW 가속기 설계
인공지능 가속기는 인공지능(AI) 알고리즘의 계산 과정을 가속화시키는 역할을 합니다. AI는 대량의 데이터를 처리하고, 복잡한 작업을 수행하기 때문에 막대한 계산 능력이 필요합니다. 하지만 일반적인 CPU나 GPU만으로는 이런 계산을 효율적으로 처리하기 어렵습니다.
이 때문에 AI 가속기가 필요합니다. AI 가속기는 AI 작업에 특화된 하드웨어로, 더 높은 성능과 더 낮은 에너지 소비를 가능하게 합니다. 이는 AI 알고리즘의 훈련과 추론 시간을 크게 단축시키며, AI 응용 프로그램의 성능을 향상시킵니다. 따라서 AI 가속기는 AI의 발전과 활용에 있어 필수적인 요소입니다.

2. Design Flow

- CNN과 FC 연산을 수행할 수 있는 kernel을 포함한 CORE를 설계 후, MOVER를 통해 데이터를 이동할 수 있도록 설계하였습니다. 이 과정에서 각각의 CORE와 MOVER의 검증을 해주었습니다.
- 이렇게 설계된 CNN, FC CORE와 MOVER를 합쳐, 하나의 Accelerator로 합쳐줍니다. 이때, HW 컨트롤을 할 수 있도록 AXI-lite를 사용하였고 Memory Map을 이용하여 제어할 수 있습니다.
- 설계한 Accelerator IP를 활용하여, Block Design으로 System을 구축하여 줍니다.
- 그 후, SW driver를 설계하여, 설계한 HW가 동작할 수 있도록 코드를 구현합니다.
(설계된 HW와 Golden Model의 결과를 비교하여 완벽히 설계되었는지 검증하였습니다.)
3. HW System
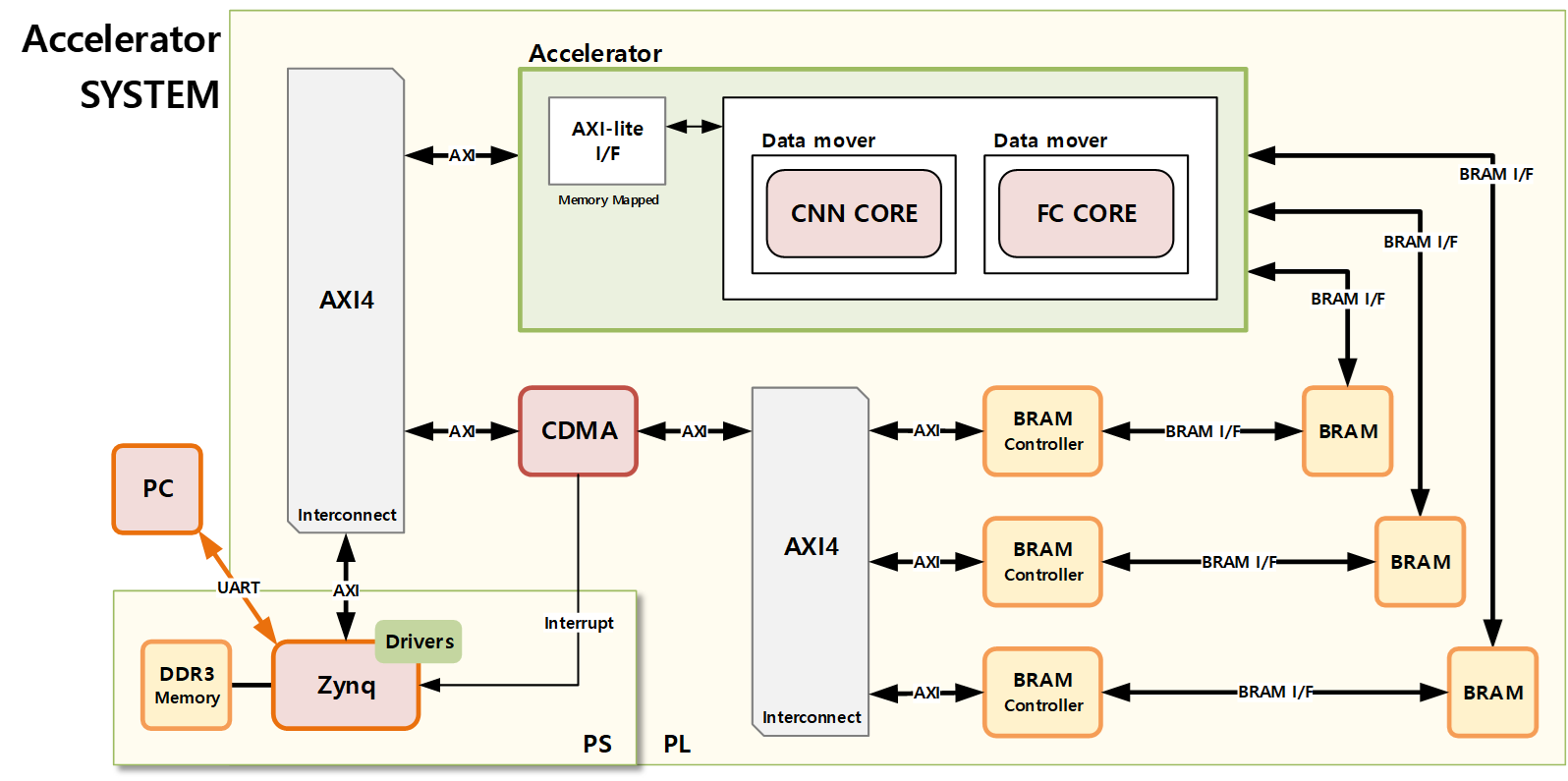
- Zynq : XILINX사에서 만든 FPGA 칩으로, PS와 PL영역을 이용할 수 있습니다. PS영역은 프로세서로 Cortex 프로세서를 이용할 수 있습니다. PL영역은 사용자가 기술한 HW를 구현할 수 있는 영역입니다.
- AXI4 : IP들 사이에서 통신을 담당하는 프로토콜입니다.
- BRAM : 연산에 필요한 데이터를 저장할 수 있는 buffer입니다.
- BRAM Controller : BRAM을 읽고 쓸 수 있는 인터페이스를 제공하는 IP입니다.
- CDMA : DDR Memory로부터 BRAM으로 데이터를 옮기기 위해 사용하였습니다. CDMA에게 명령을 내리면 시스템 프로세서 처리와 별개로 데이터를 옮겨주며, AXI 프로토콜을 사용하여 데이터를 옮겨줍니다. CDMA의 데이터 이동이 종료되면 Interrupt를 통해 알 수 있습니다.
- Accelerator : 직접 설계한 가속기의 IP로 AXI-lite를 통해 제어할 수 있습니다.
4. HW Processing
설계한 System의 동작 과정입니다.

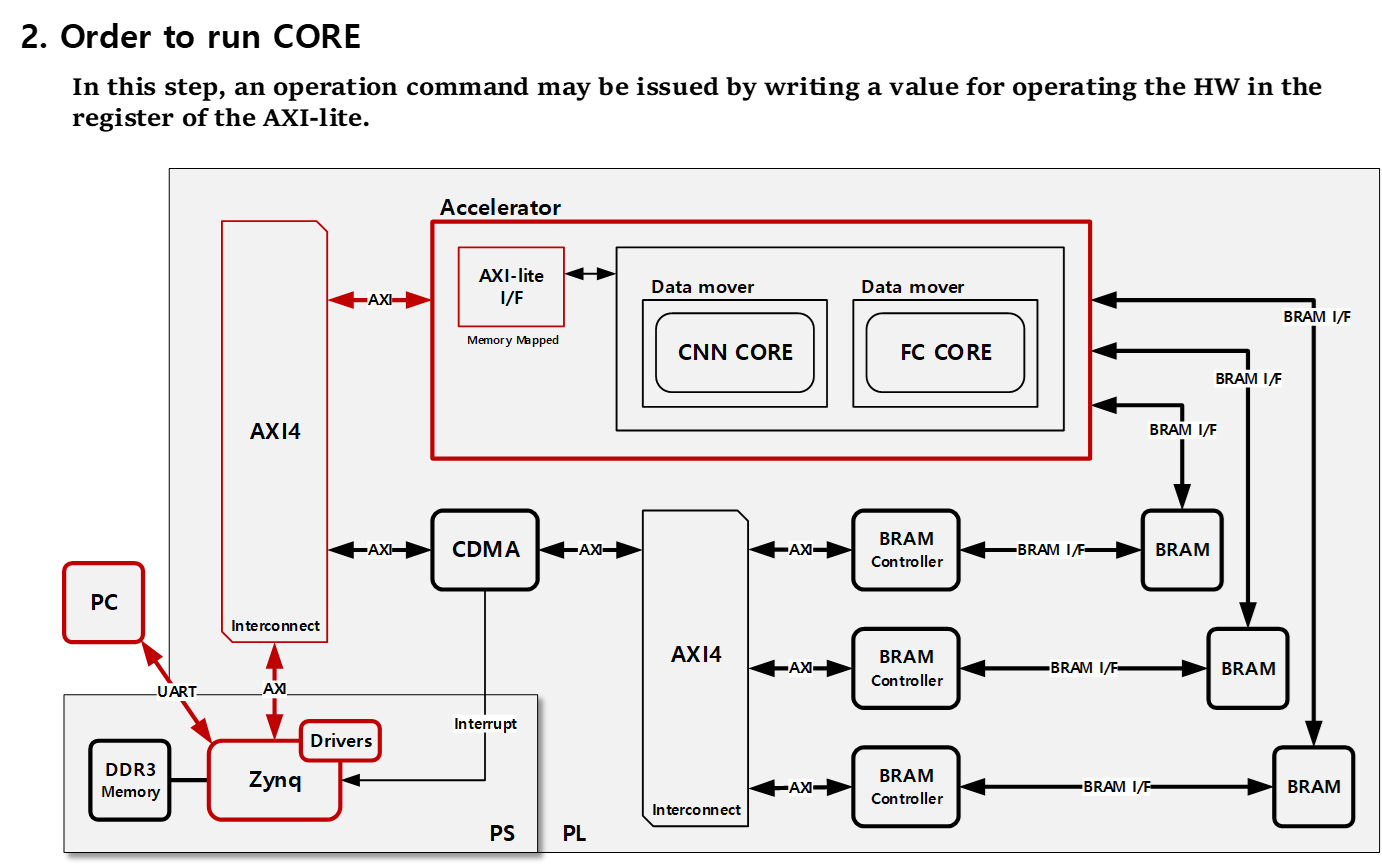



5. Accelerator Scheme
설계한 Accelerator IP의 상세 구조에 대한 설명입니다.

1) Memory Map
설계한 Accelerator는 AXI-lite 내부의 Register에 값을 쓰고 읽음으로써 제어할 수 있습니다.

- 0X0 : Control Register로 CNN/FC CORE에 동작 명령을 줄 수 있습니다.
- 0X4 : Status Register로 CNN CORE의 동작을 확인할 수 있습니다.
- 0X8 : Status Register로 FC CORE의 동작을 확인할 수 있습니다.
2) CNN Core/Data Mover
# CNN CORE
일반적으로 CNN연산을 수행하는데 있어서, Input Feature Map은 3x3보다 큰 구조를 가지고 있습니다. 아래의 그림이 그 구조를 보여주고 있습니다.

위와 같은 모델을 예시로 들면 28x28 크기의 Input Feature Map을 가지고 있다. 이러한 큰 모델을 돌릴 수 있는 가속기가 존재하고 설계할 수 있으나, FPGA의 리소스가 굉장히 많이 필요하다는 단점이 존재합니다. 그렇기 때문에 보통 CNN CORE라고 하는 가속기를 설계하고 이 CORE를 여러번 재사용하여 리소스의 효율을 높이는 방법을 사용합니다.
CORE는 HW로 구성되어 FPGA의 PL 영역에서 연산을 수행한다. 이러한 CORE 구조의 예시는 아래 그림과 같습니다.

위 CORE는 이번에 우리가 설계한 CORE이며, 원하는 방향성에 따라서 그 구조를 변경할 수 있다. 이번에 설계한 CORE의 구조는 3x3 연산을 수행할 수 있는 구조를 가지고 있습니다. 그리고 이 연산은 HW로 구성되어 FPGA의 PL 영역에서 연산을 수행합니다. 그렇다면 3x3보다 큰 Input Feature Map은 돌릴 수 없는가?라는 질문에 대해서는 그렇지 않다고 답하고 싶습니다. 만약 5x5 크기의 Input Feature Map가 필요하다면 3x3 연산을 수행하는 CORE를 9번 SW 영역에서 잘라서 넣어주면 됩니다.
설계한 CORE의 구조에 대해서 설명을 하자면, 먼저 3x3 Input Feature Map과 3x3 Weight를 서로 곱합니다. 그렇게 되면 3x3의 결과가 나오는데 이를 누적 덧셈을 해줍니다. 여기까지가 kernel의 동작입니다. 즉, kernel은 곱하고 누적 덧셈을 해줍니다. 이러한 kernel을 CORE의 OUTPUT 개수만큼 병렬로 계산을 해줍니다. 위와 같은 그림의 예에서는 곱하고 누적 덧셈하는 과정이 32번 병렬적으로 수행된다고 할 수 있습니다. 이러한 병렬 계산을 수행한 뒤, Bias를 더하고 활성함수를 통과하는 과정을 거쳐 CORE의 연산이 끝납니다. (이번에 설계한 CORE에서 활성함수는 사용되지 않았습니다.)
(Note) 본 포스팅에서는 코드를 제공하지 않습니다. __
Test Bench
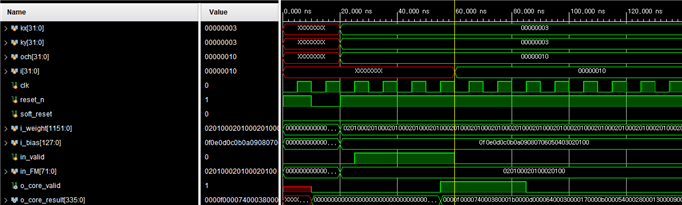
# CNN Data Mover
CNN CORE를 단독으로 사용할 수는 없습니다. 이 이유는 CNN CORE는 BRAM으로부터 데이터를 읽고 쓸 수 있는 인터페이스가 없기 때문입니다. 그렇기 때문에 BRAM으로부터 데이터를 읽고 쓸 수 있는 인터페이스를 가진 DATA MOVER가 필요합니다. 이러한 DATA MOVER와 CORE를 연결하고 포함한 모듈이 이번에 설계할 CNN CORE MOVER입니다. 아래는 설계한 CNN CORE MOVER의 구조를 보여주고 있습니다.
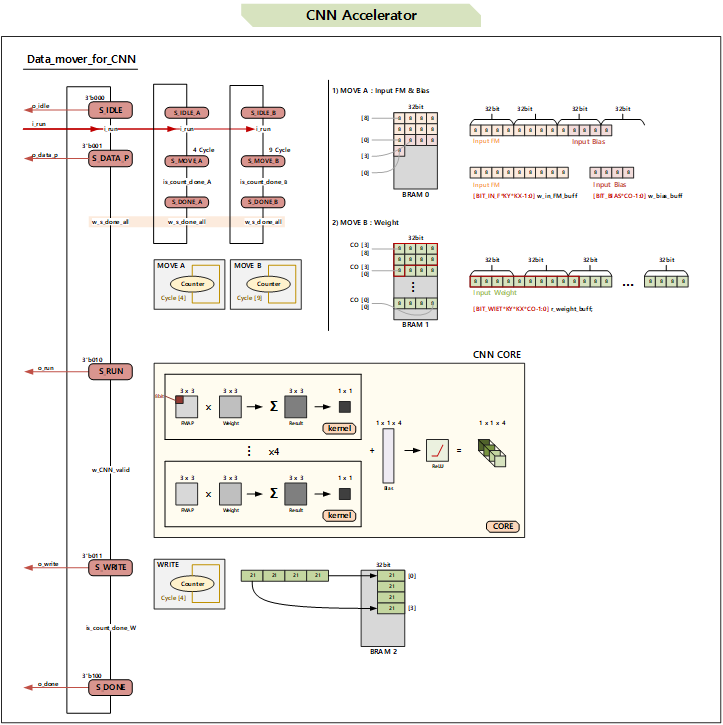
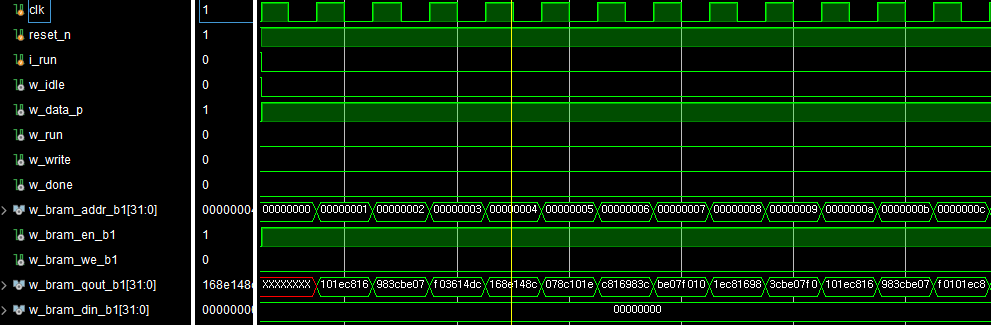
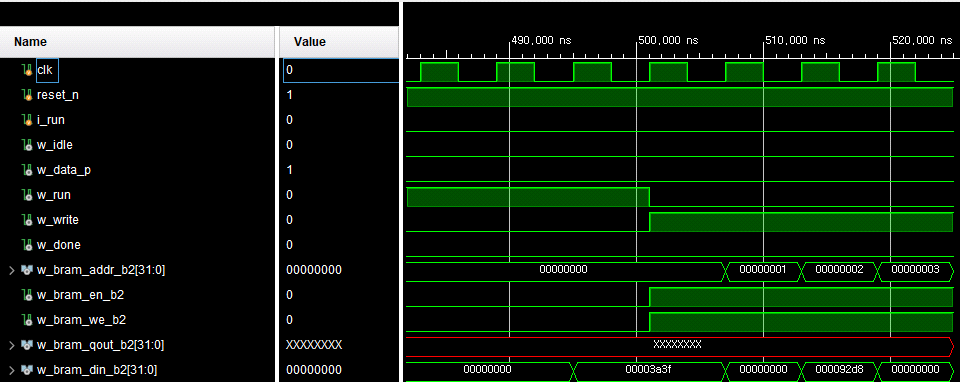
RUN 신호가 들어오면 HW가 작동한다.
MOVER는 5가지 상태를 갖습니다. IDLE, DATA_Processing, RUN, WRITE, DONE의 상태를 갖습니다. HW로 구현하기 위해 각 상태를 천이시키는 FSM을 설계하였습니다. 각 상태에서의 동작은 다음과 같습니다.
- IDLE : 대기 상태
- DATA_Processing : CORE에 데이터를 한번에 넣어주기 위해 DATA를 BRAM에서 가져와 Buffer에 넣어주는 상태
- RUN : CORE가 동작하는 상태 (CNN 계산을 수행)
- WRITE : CORE가 계산한 결과를 다시 BRAM에 쓰는 상태
- DONE : 모든 동작이 완료되었음을 알려주는 상태
Test Bench




3) FC Core/Data Mover
# FC CORE
FC(Fully Connected) 연산은 인공지능 모델의 마지막 단계에 많이 사용되는 연산입니다. CNN이 2차원 MAC연산이었다면 FC는 1차원의 MAC연산이라는 차이점을 가집니다. 아래는 FC CORE의 구조를 보여주는 그림입니다.

FC CORE는 CNN CORE와 같이 input, weight, bias로 이루어져 있습니다. 설계한 FC구조는 36개의 input과 weight를 누적 덧셈하여 bias를 더하는 kernel 2개로 이루어져 있습니다. 즉, kernel이 2개인만큼 1번의 CORE연산은 2개의 결과를 만듭니다.
# CNN Data Mover
위에서 FC CORE를 설계하였다. FC CORE는 MAC연산을 1차원으로 하는 CORE였습니다. 하지만 이러한 FC CORE를 단독으로 사용할 수는 없습니다. 이 이유는 FC CORE는 BRAM으로부터 데이터를 읽고 쓸 수 있는 인터페이스가 없기 때문입니다. 그렇기 때문에 BRAM으로부터 데이터를 읽고 쓸 수 있는 인터페이스를 가진 DATA MOVER가 필요합니다. 이러한 DATA MOVER와 CORE를 연결하고 포함한 모듈이 이번에 설계할 FC CORE MOVER이다. 아래는 설계한 FC CORE MOVER의 구조를 보여주고 있습니다.

Test Bench


5. AI Model Design
설계한 모델에서 CNN과 FC연산만 HW로 수행하고 나머지는 SW연산으로 처리한다. 각 연산의 수행은 다음과 같습니
다.

1) Stage 1
Stage 1에서는 주어진 6x6 Input 모델을 Padding 처리하여 3x3사이즈의 모델 6x6으로 바꾸는 과정을 수행합니다.
이 과정은 HW로 연산을 수행할 때, Input을 잘라 넣어주기 위한 전처리 과정입니다.

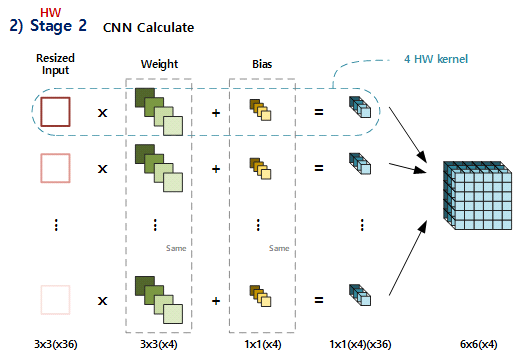
2) Stage 2
Stage 2에서는 주어진 Stage 1에서 resize된 결과를 HW로 CNN연산을 수행합니다.
3) Stage 3
Stage 3에서는 Stage 2에서 수행한 결과를 SW적으로 Pooling 연산합니다.

4) Stage 4
Stage 4에서는 Stage 3에서 수행한 결과를 SW적으로 Flatten 연산합니다.

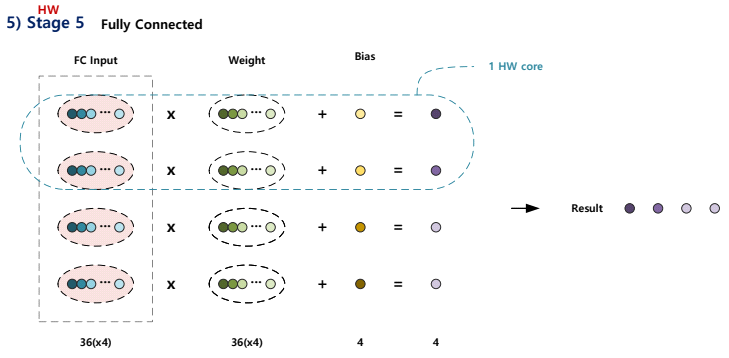
5) Stage 5
Stage 5에서는 Stage 3에서 수행한 결과를 HW로 Fully Connected 연산을 수행합니다.
6. C_ Simulator 설계
C로 설계한 시뮬레이터는 HW가 정상적으로 설계되었는지 검증하는 역할을 수행합니다.


아래와 같은 데이터가 생성되었고 이를 검증용으로 사용할 수 있습니다.

코드의 계산 결과는 터미널에서 확인할 수 있습니다. 아래는 그 결과입니다.


...
7. C_ driver 및 main system 설계
HW를 컨트롤하기 위해 driver를 설계하고 인공지능 모델을 C로 구현하였습니다.


핵심 코드는 다음과 같습니다.
cdma_controller((u32 *)ddr.flatten_output, (u32 *)CDMA_BRAM_MEMORY0, "DDR0 to BRAM0", 4*FC_BRAM0_CYCLE);CDMA로 BRMA/DDR 사이 데이터를 옮기는 코드
if (status_addr == ACCEL_CNN_STATUS) // CNN
Xil_Out32((u32) ACCEL_CONTROL, (u32)0x1);
if (status_addr == ACCEL_FC_STATUS) // FC
Xil_Out32((u32) ACCEL_CONTROL, (u32)0x2);
Xil_Out32((u32) ACCEL_CONTROL, (u32)0x0);원하는 코드를 동작시키는 코드
8. Verification
1) Waveform
설계한 시스템에 Vivado ILA를 포함하여, 신호를 트리거하여 디버깅할 수 있다. 아래는 그 Waveform이다.


2) Golden Model 비교
C로 Golden Model을 설계하였고, 이를 System에서 수행한 결과와 비교하여 검증을 하였다.

9. Result
인공지능 연산을 빠르게 수행할 수 있는 가속기를 설계하였고, 검증 결과 잘 설계되었음을 확인할 수 있었다. 이 과정에서 많은 버그가 있었고 많은 시간을 소모하였다. 최종 HW와 SW 비교 결과, CNN연산에 있어서 가속기가 SW보다 1.5배 빠르고 FC 연산에 있어서는 가속기가 SW보다 2.37배 더 빠르다는 것을 확인할 수 있었다. 이는 SW보다 빠르게 연산을 수행할 수 있다는 점에서 가속기의 이점을 보여주는 부분이다.


10. Conclusion
인공지능 가속기가 소프트웨어에 비해 기대했던 성능 차이를 달성하지 못한 이유는 다양한 제약과 한계 때문이지만, 이에 대한 해결 방안이 존재합니다. 또한 데이터 양이 증가하고 연산량이 늘어날수록 인공지능 가속기의 이점이 더욱 부각될 것으로 예상됩니다. 특히 개인이 아닌 기업 차원에서의 연구와 투자가 늘어날 경우 더 좋은 결과를 얻을 수 있을 것으로 기대됩니다.
인공지능 가속기는 대용량의 데이터를 효과적으로 처리하기 위한 중요한 도구로 인식되고 있습니다. 기존의 CPU만으로는 처리가 어려운 규모의 데이터를 효율적으로 다룰 수 있어, 인공지능 분야에서 핵심적인 역할이 될 것으로 기대하고 있습니다. 또한 GPU는 전력 소모가 크고 단순한 연산에 주로 특화되어 있어, 대규모의 복잡한 모델이나 다양한 유형의 연산을 다뤄야 하는 인공지능 작업에는 한계가 있습니다. 이러한 제약은 인공지능 분야에서 강조되고 있어 새로운 인공지능 가속기의 필요성을 불러일으킨다. FPGA나 ASIC을 이용한 가속기는 특정 연산에 최적화된 하드웨어를 구현하여 GPU보다 뛰어난 속도와 전력 효율성을 보일 수 있습니다.
이러한 특성으로 인해 4차 산업혁명 시대에서는 새로운 형태의 인공지능 가속기가 점점 더 필수적으로 여겨지고 있습니다. 따라서 가속기의 지속적인 발전과 연구가 예상되고 있습니다. 인공지능 가속기는 다양한 응용 분야에서 높은 성능과 효율성을 제공하여 현대 기술의 발전을 이끌어 나갈 것입니다.
Sun Hong
'Project > Hardware Project' 카테고리의 다른 글
| FSM Slot Machine (0) | 2023.12.01 |
|---|---|
| Wallace Tree Multiplier (0) | 2023.12.01 |
| 8_bit Breadboard Computer (0) | 2023.12.01 |
| [임베디드] IOT를 접목한 본격적인 자판기 using RaspberryPi (0) | 2023.11.26 |
| 5-Stage Pipelined Processor (RISC-V) (0) | 2023.11.17 |
Tag



